
Con i dati, verso una medicina di precisione
L’essere umano è probabilmente il sistema più complesso esistente in natura e per conoscere meglio il nostro stesso funzionamento raccogliamo sempre più dati su di noi e sull’ambiente che ci circonda.
Per comprendere l’impatto che l’uso di questi dati hanno sulle nostre condizioni di salute e sulla qualità della diagnosi e della cura, abbiamo intervistato un esperto di sistemi complessi, Enrico Capobianco che all’Università di Miami si occupa di biologia computazionale e bioinformatica.
I DATI SONO DIVENTATI UNA MONETA CHE, PER ESSERE SCAMBIATA, DEVE ESSERE NECESSARIAMENTE COMUNE
Siamo nell’era dei Big Data, ma di cosa parliamo realmente?
Il termine in questo momento probabilmente è un po’ abusato, ma questo è fisiologico. Non mi sorprende il fatto che ci sia anche una certa confusione in merito. Stiamo parlando di una vera rivoluzione in atto che cambierà i connotati della ricerca nei prossimi anni. Non c’è un solo settore interessato: si tratta di una trasformazione profonda e trasversale perché i dati sono nella realtà quotidiana, nelle aziende, nelle ricerche degli studiosi e in particolare in quelle che investono la vita delle persone in tutti gli aspetti.
 Enrico Capobianco
Enrico Capobianco
University of Miami, Center for Computational Science
Lead senior bioinformatics scientist
La definizione di Big Data è ibrida, non c’è soltanto il richiamo alle “tre V” degli inizi: volume, velocità e varietà. A me piace l’espressione dei Big Data come riflesso della global fluency, ovvero il fluire globale di informazioni a tutti i livelli della nostra vita. Un altro importante aspetto è la data liquidity. L’informazione è quantificabile, circola, si diffonde. Ha ritmi e volumi completamente diversi e inusuali rispetto al passato. I dati diventano di fatto una moneta che, per essere scambiata, necessariamente deve essere comune. Prima i dati erano una faccenda elitaria, solo qualcuno riusciva a dare loro un valore. Ora sono una liquidità, sono una merce che viene scambiata facilmente, ma che richiede ancora (e in misura crescente) molto lavoro per il beneficio di tutti e non di pochi, così da diventare strumento democratico. A livello commerciale, il valore economico dei dati è più facilmente quantificabile perché a partire da essi si possono predire i consumi e quindi incrementare i profitti. Spostando il discorso su un ambito scientifico, come quello medico, i fattori non cambiano a livello strategico. Mettendo insieme tutti i dati di un paziente è possibile definire dei profili di rischio più precisi e attendibili. Il beneficio per le persone è chiaro in questo secondo contesto, meno nel primo di carattere commerciale.
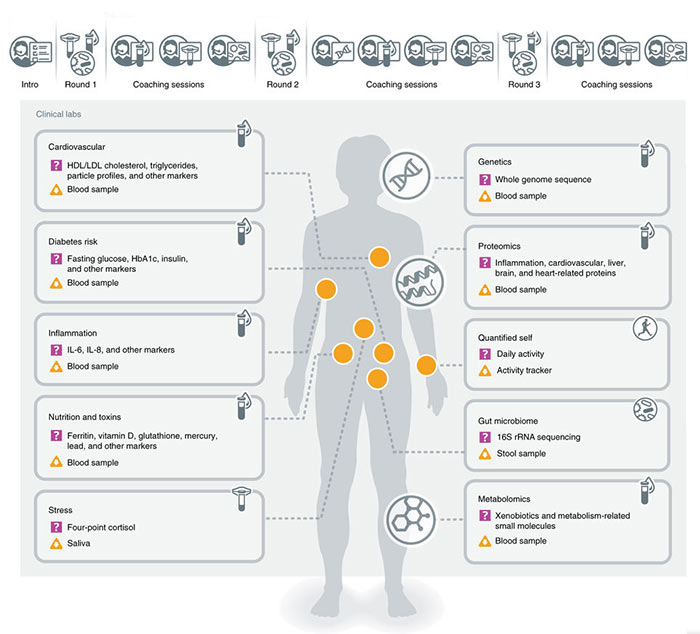
DATI CHE AIUTANO A PREVENIRE LE MALATTIE
Attraverso lo studio delle traiettorie di salute è possibile avere informazioni sugli individui durante l’arco della loro vita e non solo durante una malattia. Studiare dati longitudinali permette di fare predizioni sull’evoluzione degli stati di salute e mettere in atto misure di prevenzione. In questo ambito, uno degli ultimi studi è stato condotto dal gruppo di Leroy Hood dell’Institute for Systems Biology di Seattle che ha monitorato un centinaio di persone per un periodo di 9 mesi. Sono state raccolte molte informazioni sul sistema cardiovascolare, i rischi del diabete, la nutrizione, lo stress, le misure genetiche e proteomiche e le misure che il paziente porta da sé con sensori e altri dispositivi.
Cresce la consapevolezza dell’importanza dei dati, ma in che modo, in ambito scientifico, si può combinare il valore economico con la necessità di garantire una loro ampia circolazione?
Siamo in una situazione con vari fronti aperti: da un lato ci sono strutture di ricerca che producono molti dati sperimentali e clinici e hanno l’obiettivo di fare pubblicazioni necessarie per ottenere finanziamenti. Produrre dati portatori di valore è il modo per dimostrare oggettivamente la produzione scientifica. Oggi il finanziamento è assegnato sui dati preliminari e i grant più importanti vengono assegnati quando si è portato a termine già il 50% del lavoro.
IL VALORE DEI DATI AUMENTA CON LA TEMPESTIVITÀ DELLA LORO CIRCOLAZIONE: PER QUESTO IL FORMATO OPEN IN MEDICINA PUÒ ACCELERARE L’IMPATTO DELLE SCOPERTE
Questo vuol dire che bisogna produrre velocemente una grande mole di dati per giustificare il valore economico assegnato ad un progetto.
I dati, tuttavia, dovrebbero trasferire valore sempre, in ogni fase che li vede protagonisti, e questo valore aumenta con la tempestività della loro circolazione. Valore della produzione e della diffusione non sempre vanno a braccetto, da un lato ci sono gli interessi dei ricercatori, dall’altro quelli dell’editoria scientifica. Rendere disponibili i dati in formato aperto è un valore sempre fatpiù sentito nel campo della medicina per accelerare l’impatto delle scoperte. Ragioni economiche tendono a rallentare questo processo. Pubblicare dati open costa sempre di più.
Quali sono gli studi più significativi fino a questo momento?
Dipende dal contesto. La tendenza nel campo di cui mi occupo è iniziata nel 2013, non a caso a Stanford dove un capo dipartimento di biomedicina si è fatto esaminare per un anno intero anche attraverso sensori su dispositivi indossabili (wearable) che lo hanno monitorato sia nelle fasi di malattia che di buona salute. Ne è seguita una pubblicazione, la prima in quest’ambito, particolarmente importante perché la condizione di paziente spesso non è permanente ma transitoria e quindi è fondamentale studiare le traiettorie di salute, soprattutto per aumentare la capacità di fare predizioni, analizzando le variazioni nel tempo e nello spazio. Curare, infatti, è molto più faticoso ed economicamente svantaggioso rispetto a prevenire. Per questo c’è una forte tendenza della medicina nella direzione di maggiore proattività.
Dallo studio di un singolo individuo si sta passando allo studio di gruppi di popolazione. Ad esempio, in Italia c’è uno studio interessante che si chiama MoliSani che sta monitorando da diversi anni la popolazione a livello regionale in Molise per comprendere i livelli di sviluppo di diverse malattie come ipertensione, diabete, colesterolo, che sono condizioni che favoriscono l’insorgere di patologie molto più gravi. Anche la nutrizione è centrale al progetto.
Allargando ancor di più la visione, c’è addirittura un’intera popolazione, quella danese (circa 6 milioni di persone), studiata in tutte le sue patologie attraverso le traiettorie di salute. Tra gli studi più recenti, ce n’è uno del 2017 sulle dynamic data clouds condotto da Leroy Hood dell’Institute for Systems Biology di Seattle, che è considerato il padre della medicina delle 4P (personalizzata, predittiva, preventiva, partecipata). La sua ricerca si è basata su 108 individui monitorati per nove mesi con misure prese in tre differenti momenti. Sono state raccolte molte informazioni sul sistema cardiovascolare, i rischi di diabete, la nutrizione, lo stress, le misure genetiche e proteomiche e le misure che il paziente porta da sé con sensori e altri dispositivi. Tutti i valori sono stati cross-correlati fra di loro e, anche grazie alla visualizzazione dei dati, è stato possibile trovare associazioni e marcatori importanti per una diagnosi precoce.
IN BIOMEDICINA UN PRIMO STUDIO IMPORTANTE È STATO FATTO A STANFORD NEL 2013 DOVE UN INDIVIDUO È STATO MONITORATO PER UN ANNO INTERO
Sempre nell’ultimo anno, Snyder e il suo gruppo di Stanford hanno fatto uno studio sui dati medici presi in persone in movimento: sono stati studiati 43 individui per 250mila misure in una varietà di ambienti. Altri studi interessanti sono fatti sull’imaging: attraverso uno studio in USA su 1.000 pazienti malati di SLA sono stati raccolti circa 6 miliardi di dati per persona.
Qual è la velocità con cui questi aspetti entrano nella sanità?
Siamo ancora in una fase di startup. I dati hanno rivelato da non molto la loro grande potenza e il mondo si sta adattando. Il mondo clinico è molto particolare perché deve fare i conti con la veridicità, ovvero, la conferma del valore dei dati. Spesso non si è ancora in grado di coprire le complessità nascoste nei dati, e nemmeno quelle palesate.
Per i medici spesso i Big Data sono un elemento astratto. Prima si studiava una coorte di pazienti che si conosceva benissimo, ben contestualizzata e caratterizzata, ora il confronto è con altre coorti che magari provengono da posti ed ambienti completamente differenti. È fondamentale per il medico assicurarsi che i dati siano raccolti con parametri integrabili e interscambiabili. Siamo ancora lontani da un uso consolidato di dati complessi da parte dei medici perché c’è una ritrosia a pensare che dentro quella complessità ci siano delle verità inconfutabili.
Nei settori ad altissima tecnologia questi cambiamenti sono molto più rapidi perché c’è un riscontro diretto del significato e della qualità dei dati che si esaminano. Ad esempio, nelle sale operatorie sempre di più entrano i robot ad operare con una efficienza e precisione notevole. In questo modo però tutto è visualizzato in tempo reale e con la messa a punto pre-intervento e le elaborazioni post-intervento si ottengono montagne di dati.
Dal punto di vista del ricercatore è necessario, tuttavia, uno sforzo per convincere i clinici che quello che si fa ha utilità. Soprattutto, il data scientist non si sostituisce al medico relativamente alla capacità di leggere e interpretare i dati, ma offre un supporto con i migliori strumenti per analizzarli correttamente.
C’è quindi bisogno di un punto di incontro tra il medico e l’informatico...
Sì, perché il clinico dovrebbe comprendere che i dati, oltre ad essere disponibili in grandi quantità, sono anche molto precisi, grazie alla tecnologia e spesso alla metodologia (statistica, AI, machine learning, reti). È da qui che si intuisce la grande attesa verso ciò che chiamiamo medicina di precisione in cui vengono collezionati tutti i dati a disposizione per ogni singolo individuo per avere una visione a 360° della persona. In questo senso parliamo di N of 1 medicine, ovvero ad essere studiato è il paziente e non più la coorte di pazienti o un insieme di persone con una determinata condizione. Un individuo è già molti dati, per l’appunto, e anche complessi. Si è capito che il paziente è unico: ogni malattia è differente per ogni paziente e ognuno reagisce in maniera diversa perché ha un proprio profilo immunologico, un contesto sociale, un ambiente di riferimento, una dieta ecc, e così anche la stessa terapia può avere effetti diversi.
La medicina sta diventando sempre più personalizzata e quindi di precisione, anche per merito della tecnologia e della diagnostica. Di fronte a tanti dati però dobbiamo dire al medico quali siano spendibili nella clinica oggi e quali domani o dopodomani, ovvero è fondamentale arrivare a delle sintesi efficaci e realistiche per dare un supporto concreto alle decisioni.
Quanto è importante sviluppare e formare nuove competenze?
C’è un bisogno assoluto di persone con competenze trasversali. Esistono oggi profili ibridi in grado di fare da ponte tra una disciplina e l’altra, ma si tratta di eccezioni. La medicina traslazionale è diventata così importante proprio perché trasferire la conoscenza è importante. Non si possono prendere i dati e metterli nella cartella clinica del medico. C’è bisogno di qualcuno che capisca il contesto di riferimento. Occorre sinergia e questa si crea nei centri integrati che non sono molti nel mondo. Ci sono sforzi dal punto di vista accademico ed iniziano a nascere i primi dottorati di ricerca sui Big Data, per ora sotto spinta industriale, ma anche la Commissione Europea sta lavorando in questa direzione. L’importante è non pensare che si nasca data scientist, lo si diventa e il contesto gioca un ruolo fondamentale, quindi richiede i giusti tempi di apprendimento e di assimilazione delle complessità in gioco.

Grazie a tecniche di visualizzazione dei dati, i valori delle ricerche e i parametri misurati possono essere cross-correlati fra loro rendendo possibile la scoperta di associazioni e marcatori importanti per una diagnosi precoce.
Data Science
La data science è l’insieme di principi metodologici e tecniche multidisciplinari volto ad interpretare ed estrarre conoscenza dai dati. I metodi della scienza dei dati si basano su tecniche provenienti da varie discipline, principalmente da matematica, statistica e informatica.
Il ruolo del data scientist è stato definito dalla Harvard Business Review nel 2012 come “The Sexiest Job of the 21st Century“. Questa professione è infatti considerata uno dei ruoli chiave preposti all’utilizzo sistematico dei Big Data nelle aziende pubbliche e private e nel mondo della ricerca.
È importante che le giovani generazioni che si avvicinano alla data science siano consapevoli del fatto che in questo campo la formazione avviene per stadi, non si può apprendere tutto insieme. Oggi i giovani ricercatori imparano le specificità nei singoli progetti. Data science è tecnica ma anche contesto, conoscenza: è un cammino di complessità condito da molte variabili.
Enrico Capobianco, University of Miami, Center for Computational Science.
In termini di infrastrutture digitali quali sono le sfide più importanti in questo settore?
Una forte tendenza anche in ambito sanitario è quella verso l’Internet of Things. Gartner stima che oggi ci sono 5 miliardi di dispositivi connessi e che cresceranno nel 2020 fino a 25 miliardi. Fra alcuni anni, ognuno di noi, sia individui sani che pazienti potrà arrivare a sommare 1 TB di dati raccolti (basti pensare che ogni TAC a bassa risoluzione è pari a circa 1 GB), arrivando a 6 TB se inseriamo anche tutto il genoma, il cui sequenziamento sarà sempre più economico e alla portata di tutti. Se consideriamo tutte le variabili e i dati raccolti dall’ambiente in cui viviamo potremmo arrivare a 1000 TB. Quindi non preoccupa tanto la potenza di calcolo, perché ormai siamo abituati alla sua rapida espansione, quanto piuttosto lo storage, che è un vero problema anche perché particolarmente costoso.
NEL 2020 AVREMO 25 MILIARDI DI DEVICE CONNESSI. OGNI INDIVIDUO, SIA SANO CHE MALATO, PORTERÀ CON SÉ DECINE DI TB DI DATI. LO SPAZIO DI ARCHIVIAZIONE SARÀ SENZ’ALTRO UNA DELLE SFIDE FUTURE
Anche se il cloud qui aiuta. Associato a questo c’è da considerare l’aspetto delle politiche dei grandi player che se da una parte forniscono spazio infinito, dall’altra pongono il problema della disponibilità dei dati, perché viene richiesto un pagamento per permetterne il riutilizzo. È importante sensibilizzare su questi aspetti la comunità della ricerca e il lavoro delle reti della ricerca, come GARR, può essere fondamentale in questo senso anche perché trasversale tra le discipline.
Siamo sempre più connessi e monitorati, cosa comporta in termini di privacy e di proprietà dei dati?
Le tecnologie producono dati per definizione. Oggi siamo in grado di creare un continuum con dati eterogenei raccolti da più fonti e che ogni individuo, anche sano, si porta dietro. Non ci sono solo i dati raccolti in ospedale: anche al termine della visita i dati continuano ad essere prodotti, in parte perché lo vogliamo noi, in parte perché ci sono sensori ambientali. Aumentando le variabili e migliorando gli standard delle tecnologie diagnostiche è come se costruissimo una matrice all’interno della quale ogni paziente immette i propri dati e li porta sempre con sé.
IL PAZIENTE SARÀ SEMPRE PIÙ ATTIVO ANCHE NELLA GENERAZIONE DEI DATI. SI PONE QUINDI UN ENORME PROBLEMA DI GOVERNANCE IN TERMINI DI PRIVACY E PROPRIETÀ DEI DATI
Questo comporta temi nuovi nell’ambito del cosiddetto patient engagement, ovvero la partecipazione attiva del paziente alla gestione del suo percorso terapeutico e assistenziale. Si pone quindi un enorme problema di governance e dovrebbe esserci una chiara disciplina sul consenso nella raccolta dei dati e sulla loro anonimizzazione. Questo processo richiede una necessaria negoziazione tra pubblico e privato. La materia è allo studio a tutti i livelli, dalla regolazione all’uso, circolazione e interscambio delle informazioni. Sappiamo anche che non è banale chiedere alla persone di portare un device diagnostico, per ragioni anche banali di comfort fino alle limitazioni varie di mobilità ed altro.
Il tasso di abbandono del device risulta una variabile da studiare con attenzione, così come la interazione uomo-macchina che ottimizza la performance del device applicato. La tecnologia ci renderà sempre più partecipi, insomma, ma richiederà anche il nostro impegno.
Nei settori ad altissima tecnologia i cambiamenti sono molto più rapidi perché c’è un riscontro diretto del significato e della qualità dei dati che si esaminano. Ad esempio, nelle sale operatorie sempre di più entrano i robot ad operare con una efficienza e precisione notevole. In questo modo però tutto è visualizzato in tempo reale e con la messa a punto pre-intervento e le elaborazioni post-intervento si ottengono montagne di dati.
Dai un voto da 1 a 5, ne terremo conto per scrivere i prossimi articoli.
Voto attuale:
