
Dati intelligenti per migliorare la città
Colloquio con Paolo Nesi
La qualità della vita di una città può essere migliorata dai dati?
A Firenze, sembra proprio di sì, purché il dato abbia una sua intelligenza e sappia non solo raccontare ciò che accade in un preciso momento ma dia anche la possibilità di predire i comportamenti, identificare prontamente situazioni critiche e aiutare gli amministratori a prendere decisioni corrette.
Ogni giorno gestiamo fino a 4 milioni di dati real time provenienti da una grande varietà di fonti: Trasporto pubblico, Meteo, Social Media, Reti Wi-Fi
Il progetto Km4City, avviato dal DISIT Lab del Dipartimento di Ingegneria dell’Informazione dell’Università di Firenze, nasce proprio per questo scopo: trasformare i dati in un valore per la città. Si tratta di un aggregatore di dati e di una serie di algoritmi a supporto delle decisioni, una piattaforma che gestisce e armonizza i moltissimi dati disponibili in città: dal traffico al trasporto pubblico, dagli eventi al meteo, dalle reti Wi-Fi all’ambiente.
Informazioni utilissime per il loro singolo valore ma ancor di più nella visione di insieme, una vera e propria sala di controllo per la città che permette di fare analisi, valutazioni, previsioni, identificazione precoce di situazioni critiche. Insomma, uno strumento concreto che consente agli amministratori di attuare le strategie migliori per la città supportandoli nelle scelte in tempo reale. Abbiamo intervistato il prof. Paolo Nesi, coordinatore di Km4City, per capire di più sul funzionamento di questa piattaforma così ambiziosa.
Prof. Nesi, come è nata l’idea di Km4City?
 Paolo Nesi
Paolo Nesi
Università degli Studi di Firenze,Dipartimento di Ingegneria dell'Informazione
Coordinatore DISIT Lab
Viviamo in un flusso di informazioni continue e la raccolta di Big Data provenienti da tante fonti non è semplice per tanti motivi: per la loro quantità, certamente, ma anche per la loro eterogeneità da vari punti di vista. Il progetto è nato con l’obiettivo di dare una soluzione a problemi ancora aperti nella realizzazione di una smart city. Alcuni di questi sono problemi tectecnici e infrastrutturali non banali da risolvere come la scarsa interoperabilità fra i dati, le licenze di utilizzo, la carenza di soluzioni tecnologiche aperte e a basso costo per trasformare dati in servizi.
Il nostro obiettivo è quello di riuscire a gestire l’enorme quantità di dati in un centro di controllo in modo da creare delle opportunità reali per i cittadini. In questo modo, attraverso una interfaccia integrata, che offre una visione completa ed in tempo reale dello stato della città e dei suoi servizi, è possibile fornire informazioni a supporto delle decisioni, analizzare la città e la sua evoluzione per migliorare i servizi, aumentarne la sicurezza e la resilienza, produrre servizi e valore sul territorio.
Km4City vuol dire Knowledge Model for the City, si tratta quindi un modello di conoscenza della città. Come è realizzato?
Raccogliamo dati da una molteplicità di fonti: dal sistema del trasporto pubblico (autobus, parcheggi, flussi veicolari, flussi di persone) al Consorzio LaMMa per dati meteorologici, da Arpat per dati ambientali alle reti Wi- Fi cittadine per i flussi cittadini, dalle nostre app a Twitter, dalle colonnine di ricarica alla rete degli ospedali.

COME FUNZIONA
Km4City raccoglie i dati (statici e dinamici) provenienti da diverse fonti e aggregatori di dati. Tali informazioni vengono acquisite su una piattaforma Big Data distribuita e portati sul database semantico di Km4City. Su questi dati vengono eseguite tecniche di Big Data analytics in real time in modo da fornire API utili per creare applicazioni. Il risultato finale è la realizzazione di app per mobile, per totem informativi o pannelli di controllo (dashboard) che in base al tipo di categoria sono utili per i cittadini o i decisori pubblici.
Tutti i dati vengono acquisiti su una piattaforma Big Data distribuita e confluiscono in Km4City che è il vero cuore e motore del sistema. Si tratta di un database semantico basato su RDF store in grado di fare deduzioni e fornire un valido supporto alle decisioni con vari strumenti per i decisori pubblici e per gli operatori.Sulle informazioni raccolte viene fatta un’analisi Big Data in tempo reale per dare suggerimenti e raccomandazioni anche agli utenti della città e della regione. Si tratta di un vero e proprio assistente personale per il cittadino, che gli ricorda cose, che lo informa per tempo, che lo stimola verso comportamenti virtuosi per l’economia sociale ed il bene della città e della comunità. Tutta la piattaforma è realizzata seguendo un approccio open source.
Come funziona il modello?
Il modello non è statico, come non è statica la conoscenza che ognuno di noi ha della propria città. Siamo partiti nel 2013, ma ancora oggi il sistema apprende e pian piano prende corpo e modella la conoscenza della città. Km4City è un’ontologia che sottende l’infrastruttura. I dati vengono raccolti in modo totalmente automatizzato e sono aggregati per interoperabilità semantica attraverso un modello ontologico che tiene conto delle relazioni tra i diversi concetti degli elementi della città e consente, tramite algoritmi e strumenti di data analytics, la deduzione semantica sistematica e il ragionamento su conoscenze della città tenendo conto dei diversi domini, oltre che degli aspetti spaziali e temporali. L'enorme quantità di dati è gestita utilizzando un database NoSQL, ovvero un “database a grafo”, e un’architettura parallela distribuita. Km4City fornisce anche delle Smart City API utili per sviluppare soluzioni personalizzate per tutti i tipi di applicazioni smart city: applicazioni mobili e web, kit veicolari, totem e applicazioni avanzate. Il prossimo 24 gennaio 2017 ci sarà una giornata di training, e il 7-8 aprile un hackathon su l’uso delle Smart City API.
Quali dati sono oggi disponibili?
Al momento l’aggregatore include moltissimi dati su Firenze e la Toscana. Abbiamo tutto il grafo strade della regione: circa 1,5 milioni di numeri civici, 16 operatori di trasporto pubblico su gomma con tutti gli orari e percorsi, le ferrovie, 21.000 paline e oltre 1000 linee bus, 200 aree di parcheggio, 800 sensori di traffico, il meteo regionale, l’ambiente e l’energia a Firenze. Ma è solo un esempio, la lista è molto lunga. Tutte queste fonti producono dati realtime: ogni giorno abbiamo fino a 4 milioni di dati.
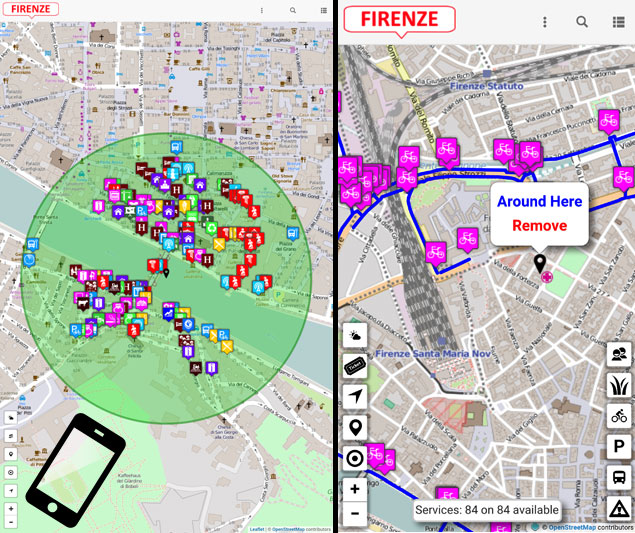
A PORTATA DI MANO
La app per dispositivi mobili Km4City è disponibile su tutti gli store dei diversi sistemi operativi e fornisce informazioni utili al cittadino in tempo reale.
Il cittadino in che modo può utilizzare queste informazioni?
Attualmente ci sono due app disponibili: “Firenze dove, cosa” e “Toscana dove, cosa”. Sul proprio smartphone, l’utente della città (cittadino, turista, studente) può ricevere direttamente le allerte della protezione civile, avere informazioni sul trasporto pubblico, conoscere i flussi di traffico, scoprire gli eventi in città, sapere dove è possibile parcheggiare, ricevere suggerimenti e assistenza. L’app funziona anche da suggeritore di scelte. Avere le informazioni giuste al momento giusto accresce la soddisfazione dei cittadini e oltre a migliorare la loro qualità della vita, li rende migliori utenti della città. Le strategie che la PA prevede per la città possono essere messe in atto solo convincendo gli utenti ad adottare comportamenti migliori stimolando le pratiche virtuose.
Quali sono stati gli aspetti più critici del vostro lavoro?
Anche tra gli Open Data c'è moltà variabilità e non tutti i dati sono utilizzabili. Per questo abbiamo sviluppato modelli di aggregazione semantica per gestirli.
Tra i dati a disposizione, abbiamo sia dati open che altri che sono privati perché contengono informazioni delicate sulla sicurezza della città. Anche all’interno degli open data c’è molta variabilità perché i dati sono prodotti da enti diversi, con protocolli diversi, in formati diversi. Avere un buon set di metadati è importante ma senza la presenza di dati di buona qualità non serve a molto. È come avere un cacciavite con un buon manico ma senza punta. Il manico è essenziale ma è il modo in cui il dato può essere realmente usato che fa la differenza. I singoli dati nascono con i loro problemi e non è possibile pretendere che siano tutti rivisti e corretti, sono i modelli di aggregazione semantica che abbiamo messo a punto a fare la differenza. Questi correggono automaticamente i problemi di aggregazione e ci permettono di dedurre cose in tempo reale, non raggiungibili in altro modo se non a costi proibitivi rielaborando tutti i dati. L’aspetto più oneroso quindi è stato quello della messa a punto del modello semantico e degli strumenti di armonizzazione dei dati provenienti da diverse fonti. Nel progetto abbiamo integrato oltre 200 open data su circa 500 categorie diverse dalla posizione delle rastrelliere, ai musei, ai bancomat e utilizzato strumenti di data mining e di intelligenza artificiale per aggregare i dati e correggere i problemi entro parametri accettabili.
Tutta la piattaforma è realizzata con software Open Source. C'è un patrimonio di documentazione a disposizione di tutta la comunità e di quanti vogliano collaborare
Questo tipo di approccio pragmatico spesso contraddistingue le tecniche Big Data da quelle tradizionali dove spesso si richiedono dati perfetti per essere usabili. In Km4City, la qualità finale del servizio dipende da come i dati vengono resi interoperabili, tramite operazioni di data intelligence per integrare, fondere e riconciliare dati in modo automatico. Il lavoro più duro è stato fatto con algoritmi per ripulire i dati in modo automatico o semi automatico. Il grosso volume dei dati permette di fare delle autocorrezioni. Per fare questo abbiamo impiegato quasi due anni, ora il motore è pronto e daremo a tutti la possibilità di caricare nuovi dati non solo della Toscana.
Il progetto è esportabile in altre città?
È quello che ci auguriamo. Al momento viene utilizzato praticamente in tutta la Toscana e a Cagliari, anche con il supporto di operatori di trasporto pubblico come: Ataf, Busitalia, Tiemme, CTTNord, Atam, e moltissime aziende in vari settori. Tutta la piattaforma è realizzata con software open source e ciò che facciamo lo mettiamo a disposizione su GitHub rappresentando un patrimonio di documentazione per tutta la comunità. Siamo disponibili a collaborare con qualsiasi entità interessata, sia per sviluppare e migliorare il modello che per utilizzarlo. Il progetto ha aperto una grande quantità di filoni di ricerca: tanti gruppi stanno lavorando allo sviluppo. Nell’ambito della ricerca italiana ad esempio sono già coinvolte le Università di Firenze, di Cagliari e di Modena e Reggio Emilia, e centri di ricerca come CNR o LaMMA.
Il progetto è cresciuto e continua a farlo nel tempo: siamo partiti nel 2013 e ora contribuiscono altri progetti come Sii-Mobility, progetto Smart City nazionale finanziato dal MIUR, Resolute e Replicate che sono invece progetti finanziati dalla Commissione Europea nell’ambito di Horizon 2020 e Ghost, un altro progetto finanziato dal MIUR su Cagliari, Torino e Firenze.
La gestione e l'analisi di una grande quantità di dati richiede grandi quantità di calcolo? Quali risorse sono utilizzate?
È vero che la gestione e l’analisi di questi dati richiedono risorse ma dal nostro punto di vista, se si ottimizzano i processi e si gestiscono in modo opportuno, non sono poi così grandi come si potrebbe immaginare. La maggior parte dei processi di acquisizione dei singoli sensori sono direttamente gestiti da Regione, Città Metropolitana, Comune di Firenze, etc. Al momento la maggior parte dei processi di acquisizione dati da gestori e la loro integraintegrazione ed aggregazione nonché elaborazione sono ospitati nel data centre del DISIT Lab, come anche i processi di acquisizione di dati dalle APP e dai social media.
Quanto è importante per l'università poter disporre di una rete come quella GARR?
La rete GARR ci permette di stare al passo con il resto del mondo e rende possibile concetti come il "Big Data As A Service"
Per l’università così come per un centro di ricerca è molto importante. Questo tipo di infrastruttura di servizio che abbiamo realizzato e stiamo facendo crescere sta fornendo servizi a un grande numero di gruppi di ricerca ed enti pubblici rendendo possibile concetti come “Big Data as a Service” che sono alla base dello sviluppo dei prossimi anni. La maggior parte delle comunicazioni e dei flussi dati fra enti pubblici passano necessariamente tramite la rete GARR che offre un servizio eccellente, che ci ha sempre permesso di stare al passo con quanto accade a livello mondiale in relazione allo sfruttamento dei dati. A questo riguardo stiamo pensando ad un approccio distribuito alla smart city in cui repliche o declinazioni di Km4City possano essere posizionate sulla rete in modo da creare una maglia smart di supporto alle nostre politiche nazionali.
 Twitter Vigilance: l'ascolto dei social
Twitter Vigilance: l'ascolto dei social
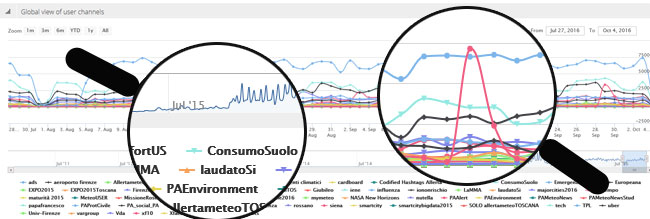
Al DISIT Lab è stata sviluppata la famiglia di strumenti Twitter Vigilance attivi 24 ore su 24 da aprile 2015. Finora sono stati raccolti e analizzati oltre 220 milioni di tweet per scopi di ricerca. Si tratta di uno strumento che offre servizi di “intelligence” per la creazione di cruscotti e viste personalizzate per lo studio di eventi e tendenze tramite metriche derivate da Twitter e consente la creazione di nuovi modelli per la previsione, la diagnosi precoce, la valutazione e il monitoraggio, in svariati domini applicativi, definibili dall’utente stesso. Twitter Vigilance colleziona in modo automatico i dati e su questi effettua operazioni di data mining, di sentiment analysis, del contenuto anche in tempo reale. Attualmente viene utilizzato per il monitoraggio dei servizi della città Firenze e per il controllo della risposta dell’utenza rispetto a eventi critici reali e potenziali, per la valutazione dei servizi di mobilità e di trasporto (in collaborazione con operatori di trasporto pubblico nel contesto del progetto Sii-Mobility), per la risposta alle problematiche ambientali e meteo in collaborazione con LaMMA e CNR IBIMET, per la valutazione dei canali e modelli di comunicazione e per il turismo anche in seno al master MABIDA su Big Data.
 Avere le informazioni giuste al momento giusto accresce la soddisfazione dei cittadini e oltre a migliorare la loro qualità della vita, li rende migliori utenti della città. Le strategie che la PA prevede per la città possono essere messe in atto solo convincendo gli utenti ad adottare comportamenti migliori stimolando le pratiche virtuose.
Avere le informazioni giuste al momento giusto accresce la soddisfazione dei cittadini e oltre a migliorare la loro qualità della vita, li rende migliori utenti della città. Le strategie che la PA prevede per la città possono essere messe in atto solo convincendo gli utenti ad adottare comportamenti migliori stimolando le pratiche virtuose.

Guarda la registrazione video dell'intervento di Paolo Nesi (KM4CITY) alla Conferenza GARR 2016
Dai un voto da 1 a 5, ne terremo conto per scrivere i prossimi articoli.
Voto attuale:
