
Corpora digitali: dalla salvaguardia alla condivisione
Nuova vita per i testi antichi con le tecniche di visual analytics. Contenuti interattivi, più ricchi di informazioni e disponibili online per tutti
L'Istituto di Linguistica Computazionale “Antonio Zampolli” (ILC) nella sua storia cinquantennale ha accumulato una grande quantità di materiali testuali che oggi sono conservati in una varietà di formati. Queste risorse, spesso arricchite con un variegato e prezioso apparato di annotazioni, rappresentano un patrimonio culturale di inestimabile valore: migliaia di testi e corpora d’autore o di riferimento per aspetti linguistici, storico-culturali e giuridici.
Per molti di questi non è ancora scongiurato il rischio di perdita, di qui l’urgenza di definire una procedura di recupero che metta al sicuro le risorse dall’inevitabile processo di obsolescenza tecnologica. Una delle prime iniziative per la costruzione e formalizzazione di buone pratiche per la conservazione di contenuti digitali è il progetto Digital Preservation Europe (DPE).
Sin dai primi tentativi di utilizzare il calcolatore per analizzare dati linguistici presso l’ILC si è sviluppato un aggregato ricco di conoscenze, esperienze, strumenti e materiali, che, avvalendosi del supporto e della collaborazione di studiosi di varie discipline (linguisti, lessicologi, lessicografi, filologi, letterati, ecc.), ha reso questo istituto un punto di riferimento nella comunità scientifica per lo studio e la realizzazione di procedure per l'analisi automatica di testi e materiale lessicale.
 Eva Sassolini
Eva Sassolini
CNR ILC, Istituto di Linguistica Computazionale
Collaboratore tecnico a supporto della ricerca
Questo ruolo pionieristico ha fatto emergere ben presto l’esigenza forte di intraprendere un progetto di recupero. Avendo collaborato alla realizzazione di patrimoni digitali redatti sin dalla fine degli anni '70, sentiamo la responsabilità di preservare queste risorse per le future generazioni. In particolare, nell’ultimo anno abbiamo collaborato con l’Accademia della Crusca di Firenze al recupero di un corpus sincronico lemmatizzato dell’italiano, estratto da periodici milanesi del quel periodo compreso tra l'800 e il '900.
Le fasi del lavoro
Il nostro approccio al recupero è basato sulla formulazione di specifici metodi e tecniche che vanno dalla standardizzazione del formato dei file e dei caratteri a quella delle annotazioni contenute. Abbiamo trovato una grande varietà di formati nei file raccolti, che ha reso il lavoro di recupero estremamente complesso. Molti testi presentano un formato ormai superato, spesso mancante di una specifica di corredo per la corretta comprensione. Servono linee guida che elenchino i dettagli necessari per ricostruire un file, stabiliscano le codifiche ammesse e elenchino le applicazioni software capaci di decodificare file simili e di restituirne il contenuto. Mancando questo tassello la ricostruzione è ardua e non sempre si ottiene una riproduzione esatta della risorsa.
OLTRE LA CONSERVAZIONE È UGUALMENTE IMPORTANTE LA CONDIVISIONE AFFINCHÉ GLI ARCHIVI DIVENTINO UNA RETE DI CONOSCENZA DISTRIBUITA
Una delle sfide più difficili riguarda la gestione di testi legati a progetti caratterizzati da interruzioni temporali. Un esempio emblematico è la storia del progetto Digesto per la sincronizzazione del testo latino e greco con la traduzione in italiano. Il progetto, iniziato nei primi anni '90, ha avuto fasi di sviluppo discontinue. Dopo una prima fase in cui fu realizzato un programma che metteva a disposizione dei traduttori le memorie di traduzione prodotte dal loro lavoro, con evidenti problemi legati all’utilizzo di un software proprietario, il progetto ha subito varie interruzioni. La più recente ripresa dei lavori ha imposto cambiamenti strutturali in corso d’opera e la sostituzione del programma con un’applicazione web, imponendo un mapping dei testi in un formato standard e condiviso.
Il progetto di recupero è diventato in seguito un protocollo costituito da una serie di fasi, più o meno articolate, di transizione, attraverso le quali un testo conservato in un formato obsoleto viene ricondotto ad uno standard. Le fasi di recupero sono potenzialmente diverse per ogni testo di cui si devono prendere in considerazione i vari aspetti: il formato dei caratteri, quello del file o dei file (quando la risorsa digitale è suddivisa in più file), quello del riconoscimento dello schema di annotazione utilizzato.
Le soluzioni adottate
Una volta assolte tutte le fasi necessarie al recupero del testo, il file salvato ha formato XML-TEI P5 con codifica dei caratteri UTF8 ed è pronto per essere messo a disposizione della comunità. A fianco di questa esigenza di doverosa salvaguardia emerge quella, non meno importante di condivisione dei risultati: perché i singoli archivi possano trasformarsi in una rete di conoscenza condivisa e distribuita, è auspicabile la loro integrazione all’interno di infrastrutture di ricerca che supportino la creazione, la fruizione, la distribuzione e la valorizzazione delle risorse. La recente partecipazione dell’Italia alla rete europea CLARIN-ERIC (Common Language Resources and Technology Infrastructure) è apparsa come un’occasione importante per approdare alla condivisione non solo dei risultati del lavoro di recupero e conservazione ma anche dello stesso protocollo. La creazione del consorzio CLARIN-IT, che trova nell’ILC il coordinamento nazionale e il nodo infrastrutturale che ospita il servizio di archiviazione, preservazione e catalogazione a lungo termine dei dati, ci consente di integrare la vasta collezione di risorse e strutture locali esistenti, attualmente scollegate, in un’unica infrastruttura di ricerca internazionale.
CLARIN HA UN RUOLO FONDAMENTALE PER INTEGRARE IN UN'UNICA INFRASTRUTTURA INTERNAZIONALE LE VASTE COLLEZIONI OGGI PRESENTI LOCALMENTE
Questa nostra iniziativa potrebbe trasformarsi così in un catalizzatore per lo sviluppo di una rete di eccellenza italiana ed europea per la ricerca nei settori del testo nell'ambito più ampio delle Digital Humanities. Per tale integrazione è fondamentale il supporto di una rete di comunicazione ad alta banda per la ricerca e l’istruzione, come GARR in Italia, collegata a livello mondiale attraverso GÉANT. Abbiamo già iniziato a popolare l’archivio con i testi già recuperati da ILC; l’intento è iniziare un percorso di valorizzazione e una condivisione più ampia di quanto rendiamo disponibile.
Le prospettive future
Le azioni di salvaguardia sono importanti, ma siamo convinti che queste non possano esaurire la funzione di stimolo che la ricerca ha l’obbligo di svolgere. La condivisione in rete è oggi imprescindibile, tutto il mondo è connesso e le aspettative dell’utente cambiano. Se invece di dedicare l’applicazione web solo al servizio della struttura degli archivi, si mettesse al centro l’utente ed i suoi bisogni informativi, le applicazioni di analisi testuale, anche realizzate per il web, non basterebbero più. Valutando cosa è già stato fatto da altri, per esempio dai francesi di Labex Obvil, che uniscono competenze di settore a quelle più recenti di rappresentazione grafica dei contenuti, anche l’ILC si è posto nuovi obiettivi. Abbiamo iniziato a utilizzare le tecniche di visual analytics per presentare contenuti anche su dispositivi mobili, che ormai oggi superano per numero di accessi ad Internet i classici PC. Questa ultima prospettiva porta con se un allargamento della platea dei fruitori, non solo addetti ai lavori, ma anche utenti comuni, più orientati ad un accesso veloce, sintetico, spesso grafico, alle informazioni.
In particolare in ambito mobile, la consultazione dei contenuti testuali si intreccia con i dati geografici e spesso avviene sul luogo stesso: attivando sistemi di notifiche, sono suggerite dinamicamente all’utente informazioni correlate al luogo in cui si trova o ad oggetti che sta osservando. Le tradizionali funzionalità di Information Retrieval dovranno quindi essere integrate con funzioni di consultazione a distanza. In particolare nel nostro lavoro di ricerca abbiamo analizzato quali tecnologie e quali supporti tecnologici potessero combinarsi meglio con le funzionalità di analisi testuale, in grado di produrre una rappresentazione dei testi in forma di grafici, mappe e alberi e possibilmente sfruttare le diverse opportunità di interazione offerte dai sensori di cui sono dotati i dispositivi mobili. Il nostro intento è rispondere all’esigenza di una maggiore diffusione di una cultura/alfabetizzazione digitale che non esaurisca il suo compito all’interno delle comunità scientifiche, ma che sia in grado di adeguarsi all’evoluzione delle tecnologie e delle modalità di fruizione dei contenuti.
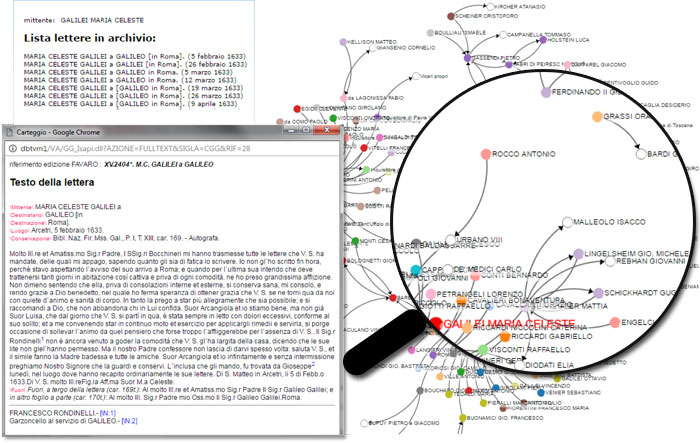
Una sperimentazione delle tecniche di visual analytics è stata condotta su una parte del Carteggio Galileiano comprendente 462 lettere relative al 1633, anno del processo e della condanna di Galileo. Il Corpus, in lingua italiana del '600, è costituito da comunicazioni personali e scientifiche espresse in un linguaggio prevalentemente informale
 Guarda la registrazione video dell'intervento di Eva Sassolini alla Conferenza GARR 2016
Guarda la registrazione video dell'intervento di Eva Sassolini alla Conferenza GARR 2016Dai un voto da 1 a 5, ne terremo conto per scrivere i prossimi articoli.
Voto attuale: